MDO for affective tests

Contents
The "MDO" control word is used on the *sub card to get Lertap to exclude cases with missing data from its calculations. MDO may be used with both types of test, cognitive and affective.
The discussion found in this topic assumes some familiarity with material found in the topics immediately preceding. If you haven't been through them, take a few minutes to read the "Missing data" topic, followed by the topic dealing with the "Did-not-see option". Then report back here.
Ready, set, go? Have a look at the following CCs lines:
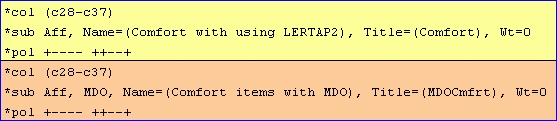
The lines above set out two subtests. Both are affective as the "Aff" control word has been used on each of the *sub cards.
Both subtests involve the same ten items; no doubt you recognize the subtest? Right -- it's the set of Likert-style "Comfort" questions found on the Lertap quiz. And, no doubt you also recall that the items themselves may be see in Appendix A of that best-seller, the Lertap manual? Very good.
The only differences between the two subtests are found in the *sub lines. The second subtest uses the "MDO" control word.
Okay; rig yourself up with a refreshment of some sort, polish your glasses, and have a gander at Lertap's reports for these two subtests.
The Statsf reports
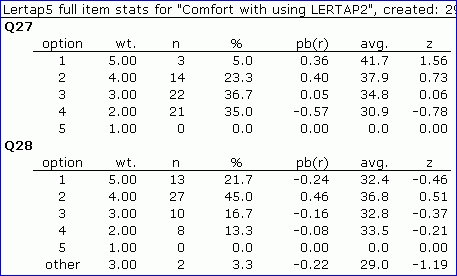
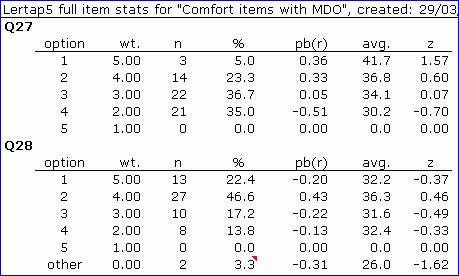
The first table above shows item stats for Q27 and Q28 without MDO, while the second table reflects the results of using MDO.
Q27's stats are the same in both tables, are they not? No-one omitted this item, so the statistics are unchanged, aren't they?
No. In fact, they're not unchanged (fooled you, eh?). Everything's the same until we get to the pb(r), avg., and z columns, wherein some changes enter.
To understand why Q27's results differ, look at the "other" row for Q28.
In the first subtest, without MDO, Lertap has wt.=3.00, giving 3.00 points to the two (2) people who did not answer Q28. Not so in the second subtest, where those two people have been stripped of scoring points. There are two different scoring methods in operation here: without MDO, people missing an answer to an item are given points equal to the average value of the wt. figures for the item's options. When MDO is active, as in the second subtest, no points are given when someone omits an item.
The result? The subtest scores will differ. Scores on the first subtest will be higher as people who miss out items are still getting points. The mean (average) of the subtest scores on the first subtest will be higher than that for the second subtest; the point-biserial correlation values, pb(r), between an option and the criterion score, the subtest score, are likely to differ, as are the avg. and z values. The more missing data, the greater these differences are likely to be.
Even though everyone answered item Q27, the criterion measure used to calculate item option statistics, pb(r), avg., and z, differs from the first subtest to the second, generally resulting in different values for item Q27's output.
Now, about Q28. As noted, two people did not answer this question. Compare the values found in the % column for Q28: they're greater in the second subtest. The % figures for Q28 in the second subtest, the one using MDO, have been calculated with n=58, the number of people who actually answered the item. In the first subtest, the % values were calculated with n=60, the total number of people taking the test (survey).
In addition, the pb(r) values for the item options seen in the second subtest have been calculated on a pairwise basis -- they are based only on the people who actually answered the item.
To read a bit more about how Lertap computes the Statsf figures, go back for a look at the "MDO cognitive, Statsf" topic.
There are two main differences between the Statsf reports for cognitive and affective subtests: it is rare for people omitting a cognitive item to get scoring points, so the statistics for cognitive item options may not be noticeably different going from no MDO to MDO. Lertap will apply a correction for inflation to the pb(r) and b(r) values corresponding to the right answer to a cognitive question, but this correction is not applied in the Statsf report for affective items (but it is for Statsb: see below).
The Statsb reports

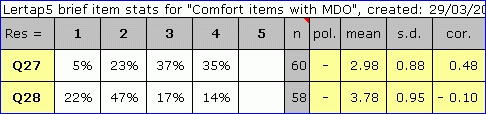
In the normal case, without the MDO option, the Statsb report for cognitive items has an "other" column which indicates the percentage of non responses to an item. This column changes to "n" when MDO is in operation, as may be seen above.
Q27 has no missing data; its mean and s.d. values are the same in both tables. The Q27 cor. figures differ for the reason found earlier in the Statsf reports: the values of the criterion measure, the subtest score, change as we go from no MDO to MDO.
Q28's figures differ almost everywhere. The percentages, mean, s.d., and cor. statistics for the second table, where MDO is having its impact, are all computed using only the responses from the 58 folks who actually answered this item. In some other data analysis systems, such as SPSS, the correlation (cor.) between Q28 and the criterion would be said to done on a pairwise basis: only when a person has data for both variables are that person's results used in the calulations.
Another note about the cor. values found in the Statsb reports: they are corrected for part-whole inflation.
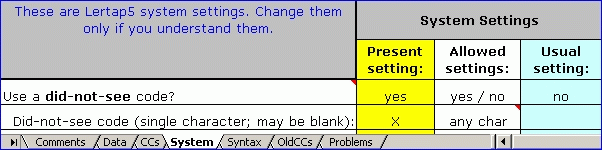
Using the did-not-see option
Suppose the did-not-see option has been turned on, with X used as the did-not-see code. The respective lines in the System worksheet would look like this:
Next, have a look at a snippet of Freqs output:

Six people did not see Q35; three did not answer it.
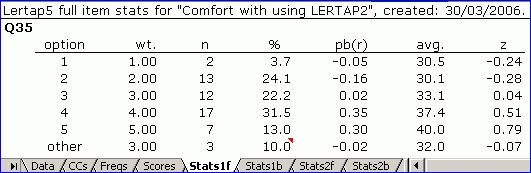
Okay? Now, suppose MDO is not operating. The Stats1f output for Q35 will look like this:
If the MDO option is turned on, the output will change:
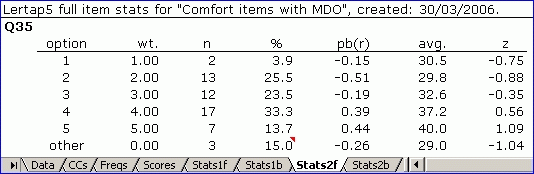
To grasp what Lertap has done, look down the % column for these two reports.
In the top report, the % values (and the columns to the right, from pb(r) to z) are based on n=54; the six people who did not see Q35 have been excluded from the calculations.
In the next report we've got MDO operating, and now we'll have n= what? Fifty-one (51). In this case, the report excludes the six did-not-sees, and the three did-not-answers.
Right. What about the corresponding Statsb reports? Thought you wouldn't ask. Here they be:


Where do you stand now? You see what happens, or are you in the did-not-see group?
Questions? Crank up your email program, and point it at: larry@lertap.com.