Creating a csv file

Contents
A "csv" file is a text file with a certain number of "fields", with each field representing a value of some sort or another.
CSV means comma-separated values. The records (or lines) in a csv file have a series of values (or fields), with commas used to separate them.
Here's an example (two commas with nothing between them corresponds to an empty field):

The csv file above came from a Lertap Stats1b worksheet which looked like this:
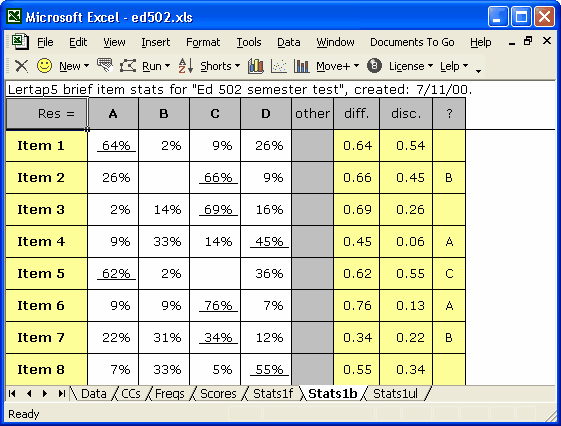
How did we get from the Stats1b worksheet to the csv file? We followed a procedure almost identical to that described in the previous topic, "Creating a text file". However, instead of asking Excel to Save as TXT (MS-DOS), we directed it to Save as CSV (Comma delimited) (*.csv).
Lertap users may have a variety of needs which prompt them to save worksheets as csv files. Among these would be a desire to use Lertap's statistics with an item banking and test development system such as FastTEST from ASC, Assessment Systems Corporation (www.assess.com). The latest versions of FastTEST have an Import Wizard which makes it a straightforward matter to pick up values in a csv file. In the example above, we'd tell FastTEST to pick up csv field #7 as the "P-Value", and csv field #8 as the "ItmTtlCorr".
The number of columns seen in a Stats1b report depends on the number of response options, or alternatives, used by a subtest's items. At times there will be too many columns, too many fields when the worksheet is saved as a csv file, for easy use with FastTEST. In this case you'll want to delete some of Stats1b's columns before making the move to save as a csv file.
Is it difficult to delete Stats1b columns? Nope; it's real easy. Use the toolbar's Shorts menu to "Turn row and column headings on/off". Then get out your mouse, and right-click on, say, column 2. Left-click on Delete, and guess what? Bingo! -- the column is gone.
Now, you know how we've been saying there may be too many Stats1b fields, and how you might want to delete some if you're making a csv move to FastTEST? Well, come to think of it, you might want to insert a new column in the Stats1b worksheet before saving it as a csv file. Yes. FastTEST assigns and carries a UniqueID field for each item. Your work might be a bit easier if you inserted a new column in the Stats1b worksheet, and typed each item's FastTEST UniqueID into it before saving as a csv file. This may speed up the task of importing the item stats.
Is it difficult to insert a new column in the Stats1b worksheet? Yep, it's real tough, about as hard as having to quaff a few ice-cold Emu Exports on a hot summer's day. (Be sure to use the Shorts menu to turn column headings on first.)
The item discrimination value seen in Lertap's Stats1b report, "disc.", is a point-biserial correlation coefficient corrected for part-whole inflation. (The manual discusses Lertap's statistics in some detail.) It is possible to get the Stats1b report to include the biserial equivalent, something which is done by turning on Lertap's "Experimental Features" option. Please refer to the following URL for a discussion of these features:
http://www.lertap5.com/Documentation/ExperimentalFeatures.htm