Lertap's Data sheet

Contents
The name of the Excel worksheet where data are recorded for Lertap analysis has to be "Data". The first two rows of the Data worksheet are for header information, as described in the definition of a Lertap workbook.
Have a look at the top of a typical Lertap Data sheet:
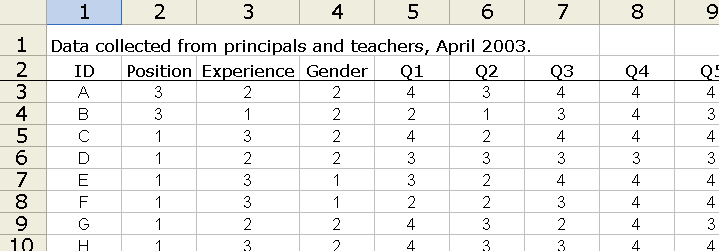
Row 1 is a general "header", or title, which can contain any information you wish, including nothing at all. Whatever is typed in this row will not appear anywhere else; Lertap doesn't read this row. This row is for your own use -- we use it to provide a brief reminder of the information contained in the Data sheet.
Row 2 also has header information. Each column has been given a header, or label: ID; Position; Experience; Gender; Q1; Q2; and so on.
For your information, the CCs sheet corresponding to this workbook had these two lines:
*col (c5-c64)
*sub aff, res=(1,2,3,4)
Item responses begin in column 5 of the Data sheet, and continue through column 64.
Lertap will use the labels found in row 2, columns 5 through 64, as item IDs. That is, the ID for the first item will be Q1; for the second item Q2; ... and Q60 for the last item (not shown above).
Item IDs can be anything, and in theory can have any length. However, we strongly suggest that items IDs be short -- not greater than 8 characters in length. Valid examples of item IDs: Item1; Preg.2; Soal3; Ques2b; SD204; Likrt17a. Having short item IDs makes parts of Lertap's output easier to read; for example, the Stats1f report has a section which looks like this:

The item IDs play a prominent role in tables such as that seen above; the longer the item IDs, the more cluttered the tables look.
If item labels are not found in row 2 of the Data sheet, Lertap will automatically create item IDs of this sort: Item1, Item2, Item3, ....
If it's desired to include ID information for the respondents, such information may be recorded in any column of the Data worksheet (but: Lertap versions dated before July 2004 have to have the ID in either the first or second column). Lertap will use the IDs to label the scores found in its Scores report, providing the respective column header begins with the letters "ID", or "id". Click here for more about this.
Excel has two reference styles used to refer to the rows and columns of its worksheets. Lertap uses what's called the "R1C1" style. In R1C1 notation, the columns of an Excel worksheet are numbers. In the other style, called the "A1" style, columns are labelled alphabetically.
Excel's default referencing style is A1. When Lertap starts up, it automatically changes this to R1C1. Later, when Lertap is closed, it will set the style back to A1 if that's what was in use before Lertap was started. (The referencing style may be manually set by Excel's Tools / Options / General tab.)
How does Lertap find the end of the Data records? It thinks it's come to the end when it finds a row whose first column is empty, or whose first column contains a blank, or whose first column contains a zero. Because of this, it is generally a good idea to see that the first column of the Data worksheet is used for something other than an item response. We say this as non-responses to items are often recorded as a blank -- try to keep blanks out of the first column.
At Lertap central, when in the process of testing out large new data sets, we often insert a blank row in the Data worksheet after row 52. This effectively fools Lertap into thinking there are just 50 respondents (remember: the first two Data rows are for header information); in turn, this lets us test our CCs cards faster, enabling us to quickly see if we've set up the cards required to get the analyses we wanted.