A half at a time

Contents
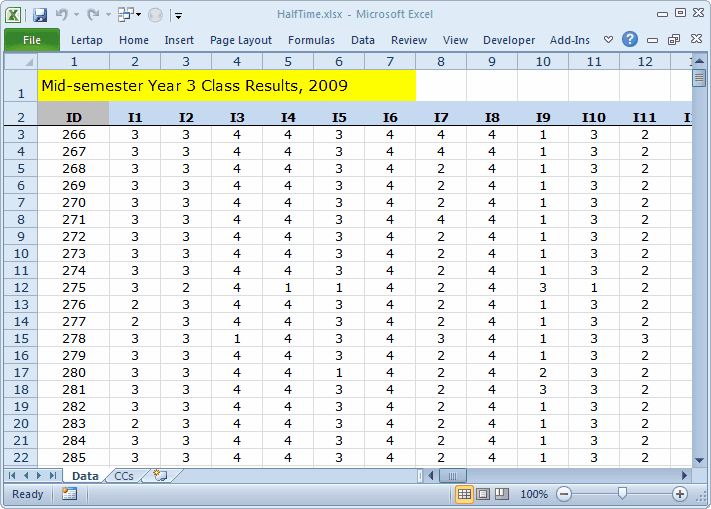
The results in the HalfTime workbook are from a 100-item mid-semester exam on statistics, administered to undergraduate educational psychology students (n=424).
The exam was meant to discriminate, to identify the strongest students. It was not a mastery test; there was no minimum score required to pass. At the end of the semester, scores on this test were included as part of the final student assessment; other assessment components included the final exam, and marks from four assignments.
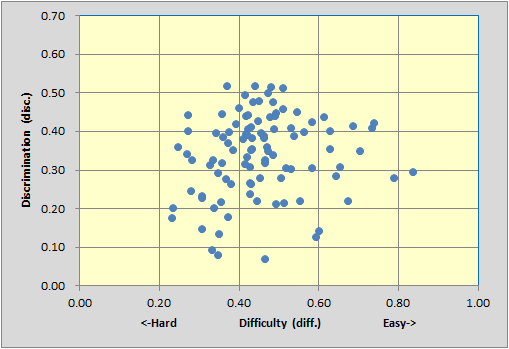
As you will see if you download the workbook, and try things out for yourself, this administration of the test had a reliability of 0.93 (coefficient alpha). Here's the diff./disc. scatter from the bottom of the Stats1b report; admire all the items with disc. values above 0.40, and note the absence of negative disc. items, contributing factors behind the nice alpha value:
What we mostly want to do with the HalfTime workbook is demonstrate how to find split-half reliability estimates by using Lertap. It's always been possible to do this in Lertap, even though, in 2005, a reviewer suggested that it wasn't (at that time we said we'd come forth with an example of how to do it, but until now we haven't). Another impetus for the present example stems from the April 2011 release of Iteman 4, another item analysis program available at Assessment Systems Corporation. Iteman 4 has several features which were not available in the previous version, Iteman 3.6. Among these is the computation of a variety of split-half reliability figures. But, you need not use Iteman if you have a split-half interest; Lertap can do the splits, too.
Should you already be wondering if you too might want to be using split-half reliability stuff, we'd suggest no. This is specialist material; not many people have a need for split-half estimates. Coefficient alpha has become the workhorse for estimating reliability (but, before alpha came along, methods for splitting a test into two parts in order to derive a reliability estimate were popular topics indeed).
But wait! Don't go away. You may not ever want to split into halves, but, nonetheless, there might very well be something in this demonstration which you'll find worthwhile as you endeavor to expand your Lertap skills. (Hope so.)
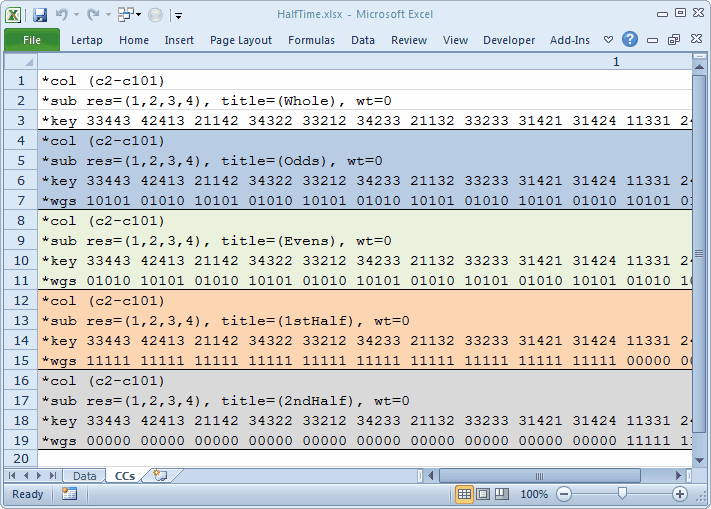
This CCs worksheet defines how many subtests? How many *col lines are there? Five. There are five subtests.
The *col lines are the same. Each subtest makes use of the same item responses. They're found in columns 2 through 101 of the Data worksheet, that is, c2-c101.
The *sub lines don't differ by much; they just give distinct "titles" to each of the subtests.
The *key lines are all identical.
It's the *wgs lines which differ.
What are *wgs lines, anyway? To get the full answer, you might care to look at the reference topic, and find out for yourself.
If you did trouble to have a look at that topic, you'd discover that *wgs is the same as *wts: the entries in the *wgs line correspond to the number of points given for the right answer to an item.
Okay, why isn't there a *wgs line for the first subtest? And, for that matter, why don't the CCs lines seen in the other samples use *wgs lines?
Because they're seldom required. When we score test items on a right-wrong basis, it's common to give one point for the right answer, zero points otherwise. This is Lertap's default action. When this default is the appropriate way to score the test, no *wgs lines are required.
Now, look at our various *wgs lines. They have ones and zeros. Zeros? Yes; we're telling Lertap to give zero points to the right answer for some items. "Hmmm", says Lertap to itself. "If he wants to give zero points for a right answer, I'm just going to ignore the item altogether".
Items with a zero on the *wgs line are not only "ignored", they are actually excluded from Lertap's reports. This is what we want to do now: exclude some of the items some of the time, depending on the subtest involved. In the split-half world, people devise ways to create two half tests. In this example, the test has 100 items, and we want to make two half tests, each with 50 items. There are a variety of ways in which this may be accomplished. Two of the most common are to split the test on an "odd-even" basis, and/or to split it by first half / second half.
The definition of the second subtest above starts at CCs line 4. We're defining the "odds" half test by (naturally) picking out only the "odd" items: the first, the third, the fifth, the seventh, and so on. These are the items to be scored, with one point for the right answer. And, we want to knock out the even items, so we give them a scoring value of zero. Thus the first *wgs line goes 10101 01010, and so on. It's picking out only the "odd" items (we should say "the odd-numbered items", but items don't always have numbers: I1, I3, I5, I7, and so on is what we mean to say).
The third subtest, starting in CCs line 8, will be our "evens" half test.
The fourth subtest, starting in CCs line 12, will be the "first half" half test. See how its *wgs line is picking out the first 50 items? You do? Good; then it will be obvious to you how we set up the second half, the fifth subtest, starting in CCs line 16.
Okay? Let's get cracking. Time for, you guessed it:
2) Use the Interpret option on the Lertap tab.
3) Use the Elmillon option on the Lertap tab. |
|
Next topic? Just click.
Tidbits:
There's more than one way to set up these subtests, to be sure. For example, we could use CCs lines like this to pick out the odd and even items, making it unnecessary to use *wgs lines:
(Note: the odd items have their responses in even-numbered columns in this sample.)
*col (c2,c4,c6,c8,c10, ...,c98,c100)
*sub res=(1,2,3,4), title=(Odds)
*key 34321 ....
*col (c3,c5,c7,c9,c11, ...,c99,c101) (For the even items.)
*sub res=(1,2,3,4), title=(Evens)
*key 34443 ....
We used *wgs lines above as they greatly ease the work. We got to use the same *col line and the same *key line for each of the subtests.
As mentioned, the *wgs (or *wts) line sets the number of points for the right answer to an item. However, it allows for just a single digit, so the points have to be from 1 to 9. To award more points, or fractions of a point, the *mws line is used. The *mws line is also used to give points for more than one answer.
There are more ways to exclude items from a subtest. The *exc line, for example, is one; an example of its use is seen in the CCs worksheet for the LenguaBIg sample.
We like to group entries on CCs lines by 5s, as seen in the *key and *wgs lines above. This makes it easier when we have to, for example, change the key for, say, item I40: it's easier to find the 40th key if we can count by 5s. But, you don't need to group by 5s. You could group by 10s. You could not group at all; maybe you're not a groupie?