Scanner data file import (1)

Contents
The momentous matters mentioned in this topic have to do with importing an "ASCII" file. Such files are often created by scanners. To learn more about such devices, scanners, try an internet search for "mark-sense reader", or "optical mark reader".
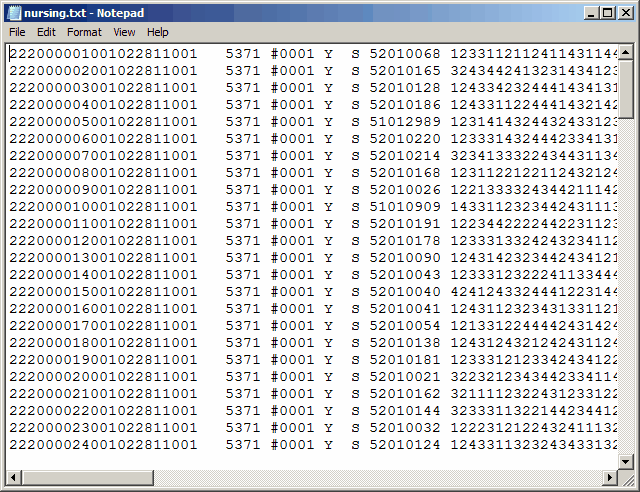
The snapshot above shows the Windows Notepad program displaying the partial contents of a data file created by a scanner.
Each line of data represents information for one student.
Each line has a number of distinct "fields", or groups, of information. The first of these has 21 characters, starting with 222. After the 222 comes a 6-character sequential code, which may be read as a number (000001 to 000024 in the lines above), followed by something which looks like it could be a date code, ending with 0001.
The second field has just four characters, 5371.
In this example, we will be interested in the contents of the fifth field (a single character, "S"), the sixth field (eight characters, 52010068 going through 52010124, as seen above), and the seventh field.
The seventh field has item responses; 88 of them. (Obviously, most of these are not showing above.)
What we'd like to do is import the contents of these three columns so that we can use the information they contain with Excel.
It's pretty easy to do.
Are you ready?
Make sure you've made a note of where the data file is on your computer. In our case, the file is named "nursing.txt", and we can't tell you the name of the folder where it's found as that would give away the source of the data, which is supposed to be confidential.
Start Excel.
File / Open

We're going to be looking for a txt file (many scanners will call their main output file a "dat" file, but today we've got a scanner tossing out "txt" files).
We tell Excel we're interested in "All Files (*.)" so that it doesn't limit our file search to just files of the type it usually favors (such as xlsx, xlsm, xlam, xls, and so on).

(The green boxes seen above are an attempt to hide the source of this example.)
Open (The Text Import Wizard swings into action.)
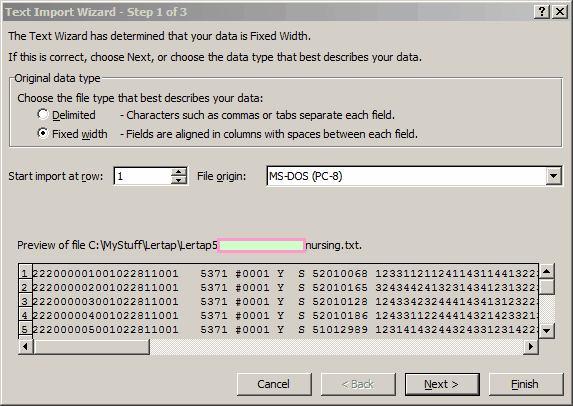
Next >
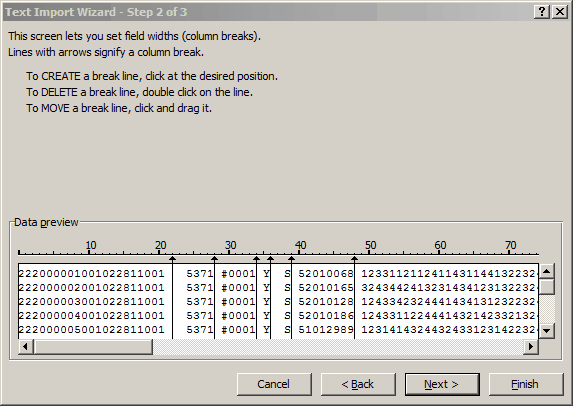
We wanted to join the field with the "S" to the next field to the right, so we used the mouse to move one of the arrows to the left:
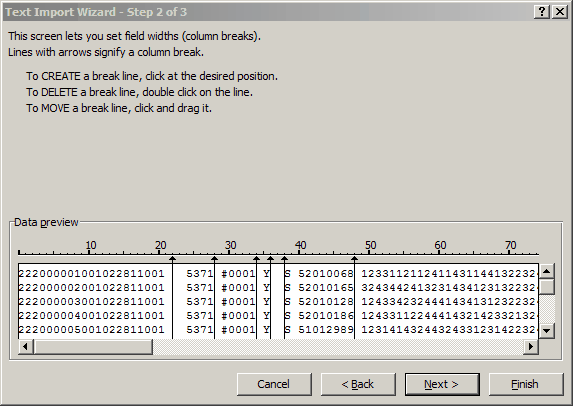
Next >
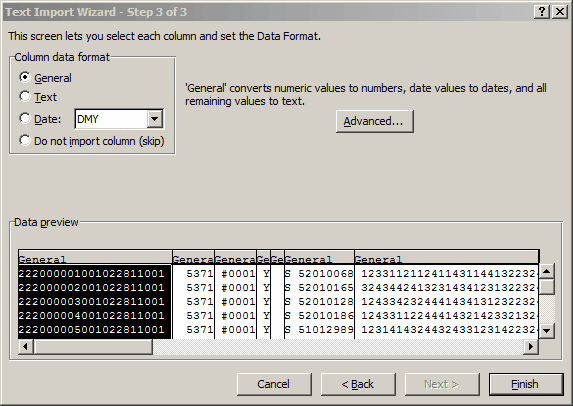
Now the Text Import Wizard has blocked off our fields, referring to each as a "column", highlighting the first one. We don't want this column, so we click on "Do not import (skip)".
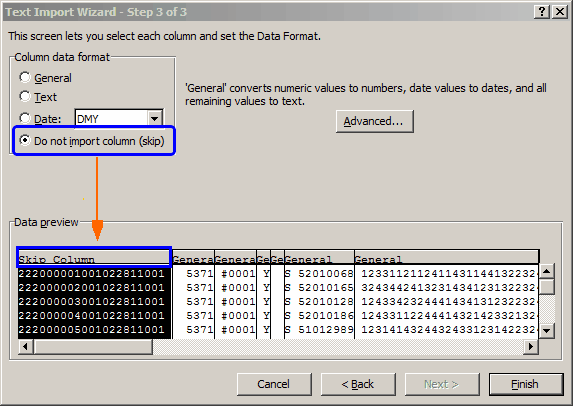
We skip the next four columns (5371, #0001, Y, and the empty one), and then tell the Wizard that the fifth and sixth columns are to come in as "Text".
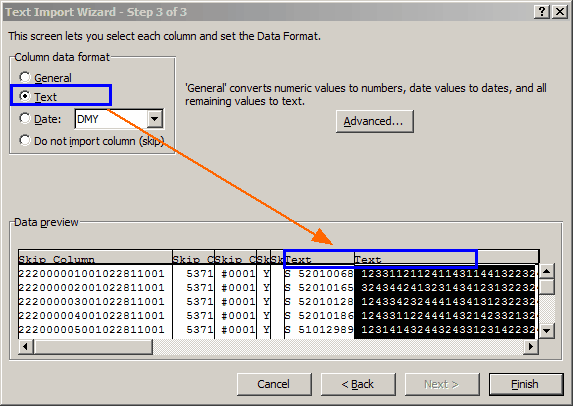
Finish
This will end the Text Import Wizard, and drop us back into Excel. Here's what we see now:

Uh-oh! There was an eighth field in the nursing.txt file which we had not seen. It's showing up here, in our new Excel worksheet, as column C. (In other words, we goofed.)
Is this a problem? Yes, in this case it is. Shortly we're going to be using "The Spreader" to dissect the long string of item responses so that each response gets tucked into its own column, and we know that The Spreader won't do it if any of the columns to the right are occupied with information. But not to worry!
We delete column C, and expand columns A and B so that we can see more contents:
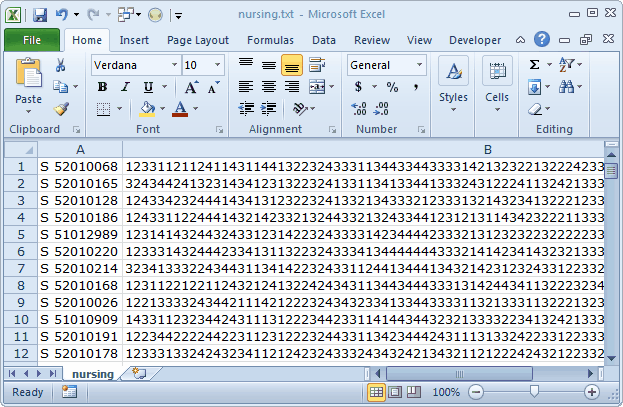
Time to party, eh?
Maybe. Nothing wrong with a nice party from time to time, but actually all we've done thus far is extract two fields of data from the nursing.txt file, bringing them into Excel by using the Text Import Wizard. Although we've gone through a fair whack of screens to get to this point, it truly takes little time to do these things once you've been through them a couple of times.
So it is that mature readers will realize that we may not merit a party yet. We've done something which the 8-year old kids raucously playing kickball next door could do without more than a 10-second pause in their game. And, anyway, what's a party without Lertap?
We have more work to do; we're not yet ready for Lertap.
Page ahead to see what we did to earn that party entry.
Tidbits:
You ASCII for something? American Standard Code for Information Interchange. (Is that what you wanted to know?)
We goofed when working on this topic, as mentioned above. However, it is certainly possible to import and use fields which may come after the field with the string of item responses. The field we forgot about above, the one which rode into our Excel workbook as column C, surprising us in the process, was actually a useful one. It contained the test score for each student, as computed by the scanner's software.
We might have done well to intentionally import this field as well. In the Text Import Wizard, we'd leave it as a "General" column (not text) -- since this is the default action, the score popped into column C above as a number, which is good. But we'd want it to be left of the column with the string of item responses. Can do? Sure; easy peasy. Insert a column before column B. The test score now moves right, becoming column D. Select it. Cut it. Paste it into column B.
(If we don't clear the columns to the right of the one with the string of item responses, The Spreader will ring alarm bells, and decline to function.)
We can then get Lertap to correlate the scanner's score with the one created by Lertap. How? Easy. Dead easy. Use an option on the Move menu, "Copy a Data column to the Scores worksheet". Easy easy easy. Hopefully the correlation will turn out to be 1.00. (The two scores should be identical; if they're not, get a new scanner -- well, maybe check the *key line in the CCs worksheet first to make sure you didn't perchance make a wee goof of your own -- endeavor to keep the scanner operators on your side; don't suggest they need a new scanner unless your department has the funds to buy it.)